


Dr. Marcel Wever
Human-Centered AutoML
It is well known that AutoML methods like the configuration of hyperparameters are essential for successfully training ML models. However, the internal process of AutoML tools and how their final result was constructed is often hard to understand, even for AutoML experts, let alone data scientists, leading to a lack of trust in AutoML systems.
Furthermore, although some experts gained insights into AutoML problems of their domains, for example an intuition for good regions of hyperparameter settings, these currently can still be difficult to inject into the AutoML process. Interacting with an ongoing process is often not possible, instead leaving the user to wait for a potentially unsatisfying result.
Therefore, we aim to make AutoML more human-centered by means of integrating both explainability and interactivity into AutoML methods. We aim to provide better insights into and adoption of these modern and efficient tools.
What is Human-Centered AutoML?
In contrast to previously purely automation-centered approaches, human-centered AutoML is designed with human users at its heart in several stages. Explainability and interactivity in conjunction with AutoML are at the core of this research focus.
We envision it to be:
- A human-centered instead of a machine-centered approach – tailored to the needs and established workflows of practitioners, thus supporting them in their day-to-day business in the most efficient and effective way.
- An understandable AutoML process that shares its insights with the developers to enable them to draw their own conclusions and learn from them.
- Enable practitioners to inject their expertise into the optimization to direct the search in the right direction directly from the start, but also continuously throughout the entire development process.
- Allowing them to inspect and intervene in the process whenever required and thus bridging the gap between the traditional interactive data science and the original press-the-button-and-wait AutoML perspective.
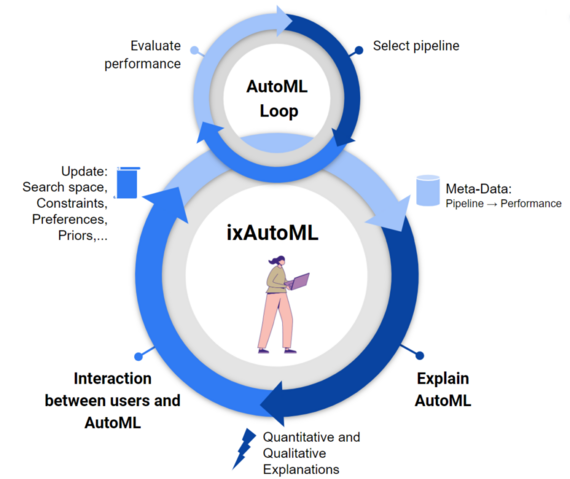
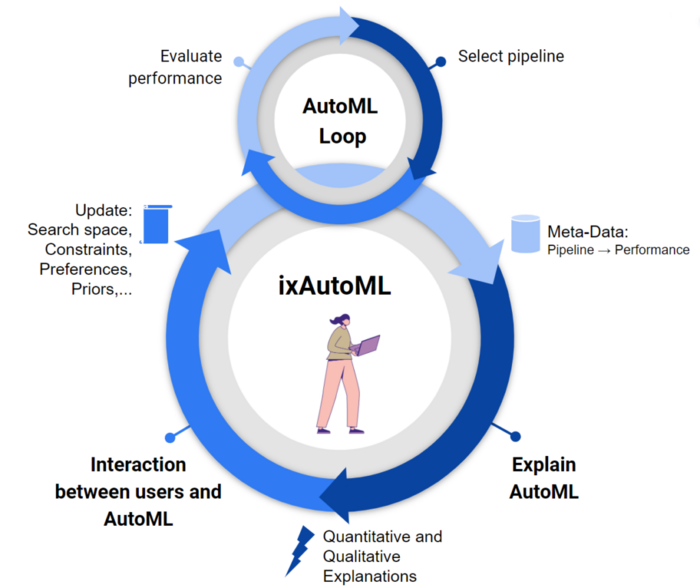
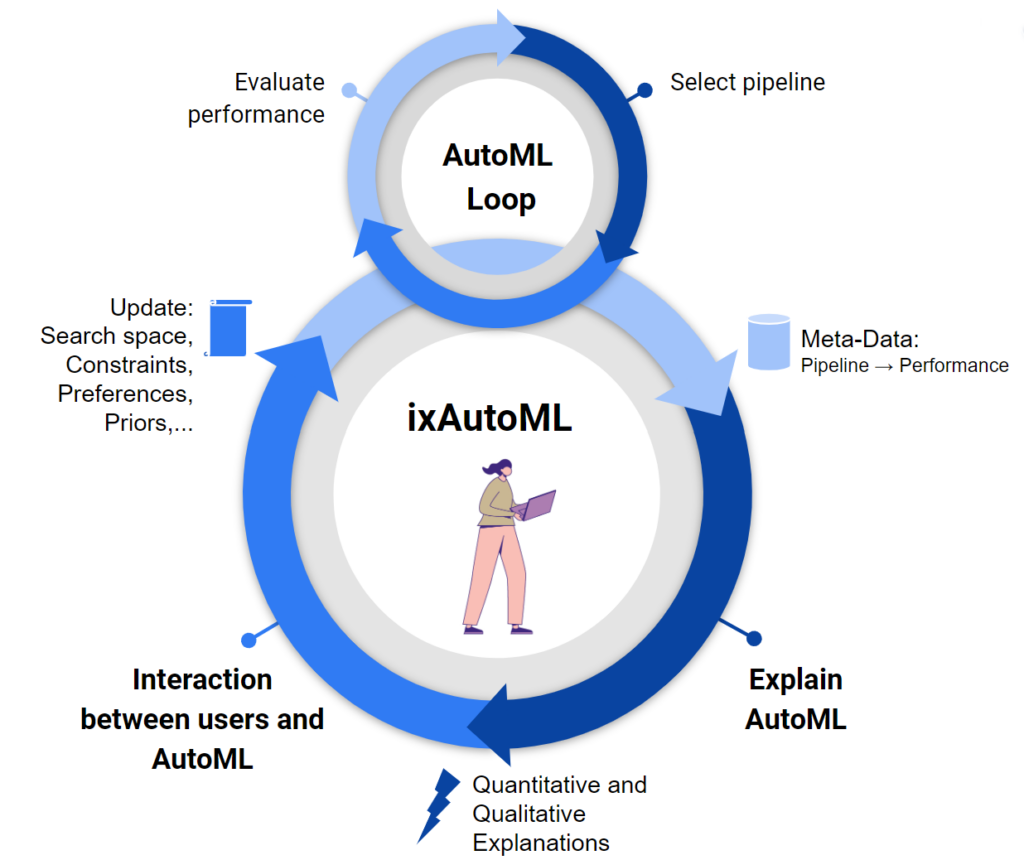
Why do we need Human-Centered AutoML?
Automating machine learning supports users, developers, and researchers in developing new ML applications quickly. The output of AutoML tools, however, cannot always be easily explained by human intuition or expert knowledge and thus experts sometimes lack trust in AutoML tools. Therefore we develop methods to improve the transparency and explainability of AutoML systems, increasing trust in AutoML tools and generating valuable insights into otherwise opaque optimization processes.
Complementary to getting insights from AutoML is the interaction with AutoML to provide further guidance from the users on how to find good solutions. For example, some experts developed an intuition for good regions of hyperparameter settings.
Trust and interactivity are key factors in the future development and use of automated machine learning (AutoML), supporting developers and researchers in determining powerful task-specific machine learning pipelines, including pre-processing, predictive algorithms, their hyperparameters, and – if applicable – the architecture design of deep neural networks. Although AutoML is ready for its prime time, democratization of machine learning via AutoML has still not been achieved.
Our Contribution
Although our group has intensively worked in various collaborations on ideas aimed at making AutoML more explainable and interactive, we still have a long way to go.
Papers:
On our webpage AutoML.org, an overview Blogpost about our vision and work on human-centered AutoML can be found www.automl.org/ixautoml/
Software:
Our library DeepCAVE is a visualization and analysis tool for AutoML (especially for the sub-problem hyperparameter optimization) runs. The framework is programmed on top of Dash and therefore entirely interactive. Multiple and diverse plugins make it possible to efficiently generate insights and bring the human back in the loop. Moreover, the powerful run interface and the modularized plugin structure allow extending the tool at any time effortlessly.
Our library SMAC offers a robust and flexible framework for Bayesian Optimization to support users in determining well-performing hyperparameter configurations for their (Machine Learning) algorithms, datasets and applications at hand.













